
Why this blog?
AI is no longer futuristic, it’s becoming essential for modern data engineering. This blog breaks down how AI can assist across pipelines, helping key areas like development, testing, optimization and reporting.
Whether you’re a data engineer, analyst or business leader, you’ll learn how AI can accelerate development, ensure data quality, reduce costs and improve collaboration by acting as a true engineering partner.
What if every stage of your data pipeline had an intelligent co-engineer assisting you to write SQL, validate schemas, optimize snowflake queries and even migrate legacy reports? This article explores how AI is becoming a co-engineer for modern data teams, transforming the entire data engineering lifecycle from ingestion to insights.
The Growing Complexity of Modern Data Pipelines:
Data Engineering today isn’t just about moving data from Point A to Point B. Pipelines are multi-layered, collaborative and continuously evolving, which introduces several key challenges:

Managing these manually is slow, error-prone and expensive – making AI a natural co-engineer to streamline workflows, enforce best practices and accelerate delivery.
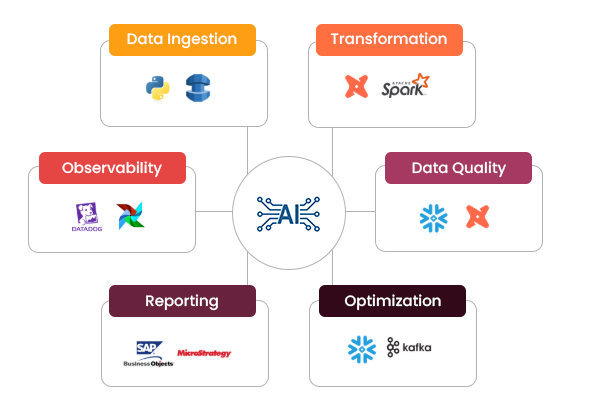
Phases of Data Engineering Lifecycle:
Ingestion
Modern pipelines ingest data from various sources like APIs or databases or unstructured images/web feed using DMS services or python scripts. Maintaining consistency across data sources is critical, especially when multiple teams consume the same datasets. AI can automatically generate scripts and monitor schema drifts in real time. For instance, AI can read sample payloads from an API and produce Python ingestion scripts that include Pydantic-based data contracts ensuring schema adherence before data enters the warehouse. This prevents downstream errors caused by inconsistent or malformed data.
Transformation
Raw data must be transformed into analytics-ready models. Even though frameworks like DBT or Apache Spark enable modular or scalable transformations, writing complex SQL or Spark logic can be tedious. AI tools help by converting natural language requirements into optimized transformation models. For example, an engineer could tell AI to “Create a daily revenue model by joining orders and customers with incremental updates” and receive optimized DBT model with documentation included. This accelerates development while maintaining best practices of transformation logic.
Data Quality and Testing
Ensuring high data quality is essential for any analytics. AI can automatically generate validation tests based on historical data patterns. For example, AI can automatically generate DBT tests for null checks, value ranges or custom SQL tests based on the tables. By embedding AI assisted checks into pipelines, teams reduce manual test writing and improve overall reliability.
Query and Cost Optimization
Cloud warehouses like Snowflake operate on consumption-based pricing, making query efficiency critical. AI can analyze query patterns and suggest optimizations. For instance, AI can examine a slow running query and recommend optimized joins, clustering or aggregation strategies, reducing runtime and compute usage. It can also flag high-cost queries and suggest warehouse resizing, query batching or scheduling adjustments. This allows teams to maintain responsive pipelines without overspending.
Reporting
Modern organizations often need to convert legacy dashboards or reports from platforms like MSTR or SAP BO to new architecture. AI can analyze report definitions and underlying queries and suggest optimized replacements and transformations. For instance, AI could read a complex MSTR report, extract its logic and generate equivalent Snowflake SQL or DBT Transformations. This can help analysts create simple dashboards and get faster insights.
Observability
Monitoring complex pipelines can be overwhelming. AI can correlate metrics, detect anomalies early and predict potential failures. For example, using snowflake query logs or Datadog metrics, AI can alert teams about unusual spikes in latency, data freshness, schema drift or pipeline failures. This proactive observability reduces downtime and improves trust in the data platform.
The Bigger Shift in Data Engineering
AI isn’t here to replace data engineers, but to help them work faster, smarter and more reliably. Modern data pipelines are increasingly complex, spanning ingestion, transformations, testing, optimizations and reporting. Managing all this manually is time-consuming and error prone.
Tools like Cursor AI act as your assistant, automating repetitive tasks, enforcing data contracts, optimizing queries and monitoring pipelines. By handling routine work, AI amplifies team’s capabilities to focus on high-value tasks, deliver insights faster and build more reliable and scalable pipelines.
Let’s build AI-powered data pipelines that move faster and cost less. Factspan can make AI your co-engineer across the data engineering lifecycle.


Mathematical Optimization for Enterprise Decision ...

PowerCenter to IDMC: A Practical Migration Playboo...

Building Scalable Data Pipelines with Alteryx and ...
