
Why this blog?
The blog introduces Snowflake’s innovative approach to data warehousing, emphasizing Stream and Merge objects for easy incremental loading. Understanding these concepts can boost data management efficiency and cut down on resource usage compared to full loads. It also showcases SnowPipe’s transformative potential for optimizing analytics workflows, making it a must-read for anyone aiming to streamline their data engineering tasks.
Snowflake is a cloud-hosted relational database used to create data warehouse on demand. Data in the data warehouse can be loaded as full load or incremental load. The full load is a process of deleting whole existing data and reloading it again. Full loads are time and resource-consuming tasks compared to incremental loads that only load a small amount of new or updated data instead of loading full data every time.
We can achieve incremental loading in Snowflake by implementing change data capture (CDC) using Stream and Merge objects. Stream object is used for change data capture which includes inserts, updates, and deletes, as well as metadata about each change so that actions can be taken using the changed data. The data captured using Stream is then merged to the target table using match and not match condition.
What are Stream and Merge?
Merge:
Merge is a command used to perform some alterations on the table, to update the existing records, delete the old/inactive records, or add new rows from another table.
Snowflake offers two clauses to perform Merge:
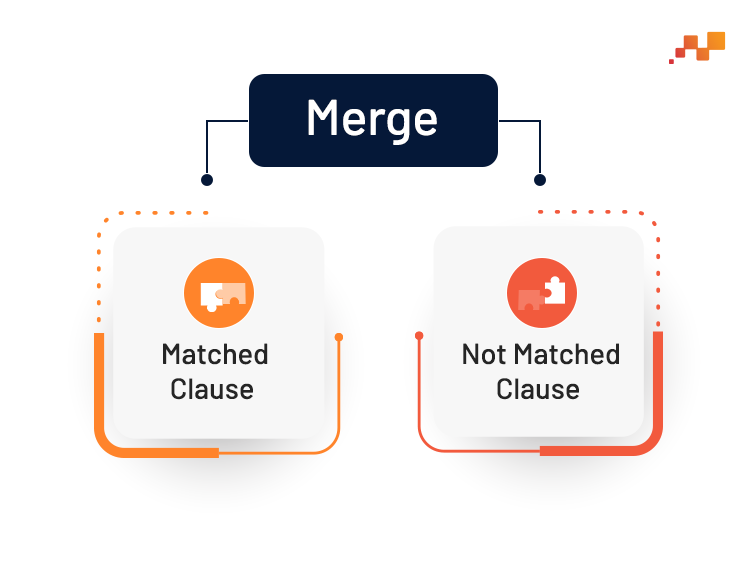
- Matched Clause: Matched Clause performs Update and Delete operation on the target table when the rows satisfy the condition.
- Not Matched Clause: Not Matched Clause performs the Insert operation when the row satisfying conditions are not matched. The rows from the source table that are not matched with the target table will be inserted.
SnowPipe: Cloud Data Ingestion Tool Powered by Snowflake
Uncover the transformative potential that SnowPipe holds for optimizing your analytics workflow.

Stream:
Stream is a table created on the top of the source to capture change data; it tracks the changes made to source table rows.
The created stream object just holds the offset from where change data capture can be tracked, however, the main data in source remains unaltered.
Three additional columns are added to the source table in a stream:
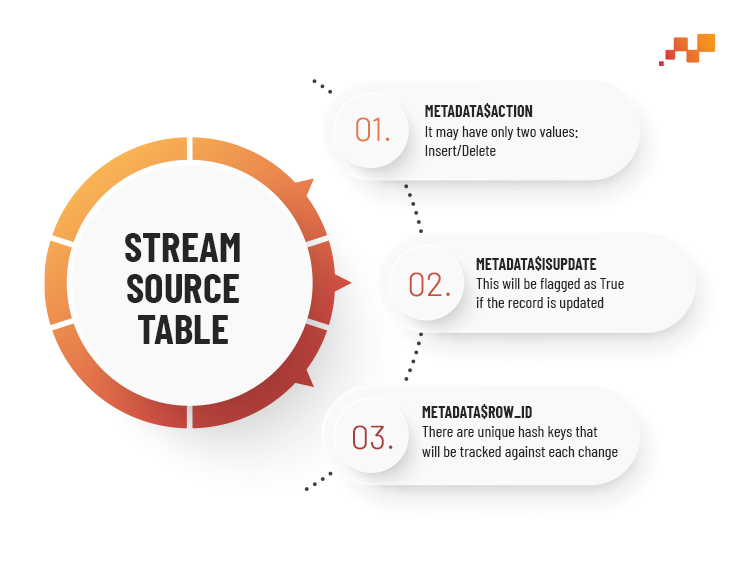
| Column | Description |
|---|---|
| METADATA$ACTION | It may have only two values Insert/Delete |
| METADATA$ISUPDATE | This will be flagged as True when the record is updated |
| METADATA$ROW_ID | There are unique hash keys that will be tracked against each change |
As we now know what Stream and Merge is, let’s see how to use Stream and Merge to load the data:
Step 1:
Connect to the Snowflake DB and Create sample source and target tables:

Step 2:
Create stream on source table using below query:

Step 3:
Let’s insert some dummy data into the source table:
AWS Data Engineering Essentials Guidebook

After inserting data into the source let’s check data captured in the stream:

As we inserted data the first time in the source the newly inserted rows will be flagged as INSERT in the METADATA$ACTION column and METADATA$UPDATE as FALSE in the stream.
Step 4:
Insert data into the target using Stream and Merge using the following query:


As we are inserting data the first time there will not be any matching personal_id in the target table and as the METADATA$ACTION flag is INSERT, the merge command will insert the whole data into the target table as it is.

Step 5:
Let’s update a few source rows and load them again to target:

As soon as we update the source table, the stream will capture these changes and update the stream data.

The updated row will be labelled as “INSERT,” while the older row that was updated will be marked as “DELETE” in the METADATA$ACTION column. Consequently, when we load updated data from the source to the target, the older row with “City Nagpur” will be deleted, and the updated row with “City Mumbai” will be inserted.
Again, run the same Stream and Merge command we used earlier to load only updated data in target, updated target data will look like this:

To automate this load process, we can create a task, this task will run after a specified time interval and load data into the target if there are any source changes.
Looking to boost your business with better data management?
Talk to our experts to see how Snowflake can simplify your data operations and drive your business growth.


The Future of Medallion Architecture with Snowflak...

Smarter Healthcare Analytics with Snowflake and Ic...

Serverless Computing in Snowflake...

A Complete Guide on Security and Compliance in Sno...

Enhancing Data Processing with Aggregate Functions...

Streamline SQL Workflow with Snowflake Copilot...

GCP vs. AWS vs. Azure (2024)...

Databricks vs. Snowflake (2024)...

Quick Tutorial on DataFrame Updates in Snowpark...
