Any organization that needs to discover distinct groupings of consumers, sales transactions, or other types of behaviors and items may find cluster analysis to be a helpful data-mining tool. For instance, banks employ cluster analysis for credit rating and insurance companies use it to identify fraudulent claims. And we know, all the organization domains would like a quick guide to Cluster Analysis that can help them in decision making.
Finding comparable groups of individuals is the goal of cluster analysis, where “similarity” between each pair of subjects refers to a general measure over the entire collection of attributes. In this article, we will discover the guide to cluster analysis for making informed and data- driven decisions.
Cluster Enhanced Information Extraction
With the help of Clustering and this experimentation, examination of a platform for enterprise blogging has been done. It explains how to get a usable subset of all the blogs that the company employees have written and published.
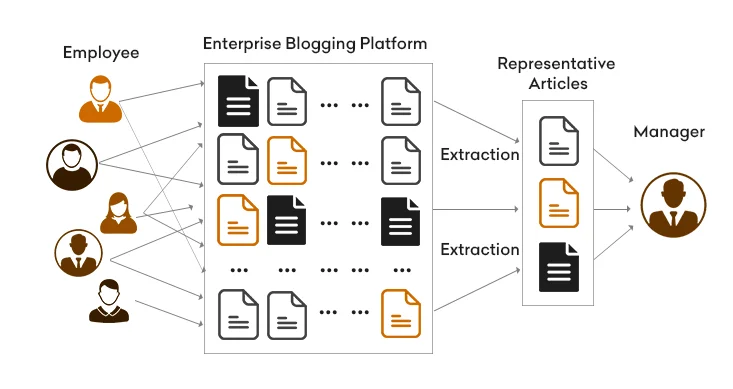
Enterprise blogging systems, it is widely assumed, would aid in the development of an adaptable intraorganizational network that might successfully allow knowledge transfer and encourage emergent ideas. Many businesses are making significant investments in internal blogging platforms and pushing their staff to have blogs. Information acquired on such a crowd-based platform is potentially valuable in assisting managerial work when staff members adopt it and regularly publish their views and writings on it. The problem, though, is the vast volume of data produced on such a network. Every week, an internal blogging system generally generates thousands of postings. Almost none of the articles will be read or even browsed by decision-makers.
In this case, extracting a small but representative subset of all the posted articles becomes a bottleneck problem of leveraging the useful information posted in enterprise blogging platforms, as illustrated in the above figure.
Solving via General Extracting Framework
To solve for the problem statement above, and to make cluster analysis helpful in decision making, our experts created the REPSET framework, which can be used to select a few representative articles from the initial vast corpus and summarize the posts made on enterprise blogging networks.
⇒ The first step in the proposed algorithm is to construct a similarity matrix, S={sij} of the posted blogs.
By TF/IDF model, a blog can be represented by a keyword vector denoted as:
di=[wi1, wi2,…., wip]
where p is the number of keywords, then the similarity of two blogs, i and j , is defined as,
s(i,j) = di • dj /(||di|| X ||dj||)
⇒ The second step is to divide the studied blogs into K groups by a specifically designed clustering algorithm. Initially, each blog is viewed as a separate cluster; then the clusters are gradually merged; at each stage, the two clusters with the largest cluster similarity [ Sim(Ci, Cj) = (1/ |Ni| • |Nj| ) ∑u∈Ci ∑v∈Cj s(i, j)] are merged together, and the boundary objects are reassigned after each merger.
⇒ The Third Step, after combining all of the blogs into a single cluster, is to create the blog hierarchy. By cutting the hierarchy at the appropriate level and utilizing a user-specified number of clusters (or desired number of representative blogs), k, a clustering result can be generated. From each cluster, a representative blog is chosen, with the most representative blog in a cluster being chosen by,
ri = arg maxj∈Ci ∑u∈Ci s(u, j)
Conclusion
Cluster analysis groups unlabeled data to extract information, and is considered crucial for data-driven management and decision-making. In fact, for healthcare systems complex applications also like analyzing a claims data collection that includes skewed healthcare expense data, cluster analysis has been proven to be a helpful statistical method.

Harnessing the Power of Artificial Intelligence to...
Tableau – A Contemporary Approach to BI and ...

Microservices in Schools and Colleges...

EdTech AI – Machine Learning facilitates Fun...

AI in Programmatic Advertising – Breaking a ...

Dawn of the AI – Art...

How Netflix Save $1 Billion a Year with AI?...
