
Consider that you manage an online store that is always open. Every minute or second, users can place orders and pay for the items. Your website will be processing a large number of customer transactions in real-time, including user IDs, credit card numbers, order IDs, and product and delivery details.
This all happens in the blink of an eye, thanks to online data processing systems, which include databases and platforms like e-commerce, CRM, and payment gateways.
In addition to carrying out regular tasks with data processing systems, your system should also be available to assess your business performance. For instance, you may want to analyze the sales of a particular product and compare it against the preceding month.

It implies you need to collect transactional data, process it using data processing tools, and then transfer it to the data warehouse so that analysts and other team members with access to BI interfaces can visualize the sales data.
Wait a minute… How do you transport relevant data quickly and reliably too? That is what data engineering is all about. To create a fast, productive, and efficient data pipeline, you need to have the necessary gear, software, and infrastructure built for it.
Before we go deep-dive into the processes, let’s take a step back and first understand why and how data engineering systems became an integral part of our digital ecosystem.
Human-operated to System-managed Data Pipelines
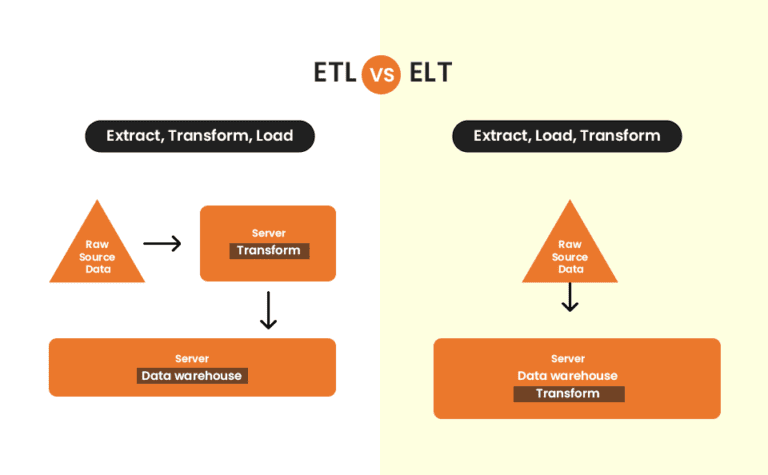
A Data Pipeline is a system that captures, organizes, and routes the data to different systems, to be utilized further to perform analysis. Within a data pipeline architecture, ETL (Extract, Transform, and Load) and ELT (Extract, Load, and Transfer) are subprocesses.
In many traditional industries, the data pipeline is still manually operated by data personnel deployed to update tables on daily-basis for business analysis. It leads to numerous human errors and data breaches, especially for organizations dealing with sensitive information like banks and insurance companies.
The transactional data were typically uploaded every night to ensure that the data is available on the next day and ready for use. However, this approach in data engineering soon became a bottleneck, especially for urgent transactions where businesses and users had to wait until the following day to act on their data.
With the changing landscape of the customer ecosystem and the increasing need for speed and convenience, immediate data access has become an integral aspect of every competitive business.
The volume and the variability of the data also expanded, pushing many companies to opt for cloud storage and computing, for scaling and cost optimization. The data’s engineers are also involved in constructing data pipelines to move data from on-premise data centers to cloud environments.

Today’s business ETL systems must also be able to ingest, enrich, and manage transactions as well as support both structured and unstructured data in real time from any source, whether on-premises or in the cloud.
Now that we have established the need for a proper pipeline, let’s take a close look into the ETL process.
What is an ETL Pipeline?
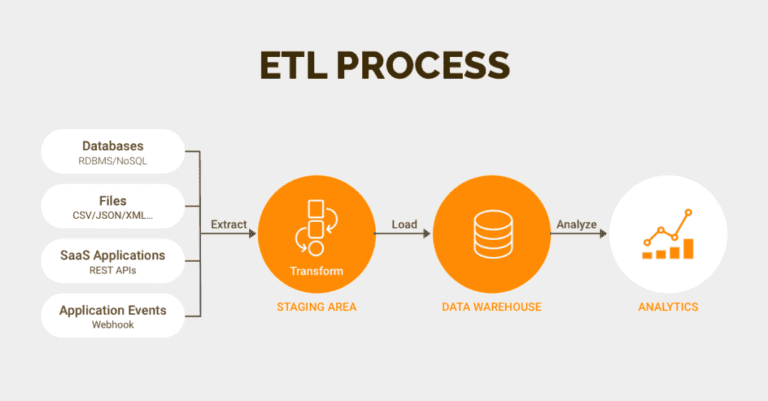
ETL, or extract, transform, and load, is a method used by data engineers to gather data from various sources, transform it into a reliable and usable resource, and then load it into the systems that end users may access and utilize later to address business-related issues.
ETL was introduced at the same time as databases gained popularity in the 1970s. The data pipeline was a way of integrating and loading data for computation and analysis. It eventually took over as the main technique for processing data for business specific data warehousing projects.
ETL process cleans and arranges data through a set of business rules in a way that satisfies particular business intelligence requirements, from as a simple monthly business report, to more advanced analytics that can enhance the back-end procedures or end-user experiences.
Extract
The initial stage in this process is to extract data from the target sources, which are typically structured and semi-structured data sets of the transaction databases, business systems, APIs, sensor data, marketing tools, and more.
Structured and Unstructured data types
Many of the day-to-day business data types are structured such as point-of-sale data, loyalty program data, transaction data, etc.
Others are semi-structured JSON server logs and unstructured data.
Data that does not cleanly fit into a normal database structure is referred to as unstructured data. Typically, it is inconsistently sourced, badly structured, and practically on Freeform. Unstructured data are frequently extracted from emails, social media posts, customer care call notes, and chats with customers on messaging platforms.
Although unstructured data is a very valuable source of pertinent data, it cannot be handled by standard data storage and regular ETL processing techniques. Separate data extraction techniques are used in the staging area before it could be stored, transformed, and joined with an already-existing structured data to start the data pipeline processing.
Transform
The second step consists of transforming the (structured and semi-structured and unstructured) data. It needs to be extracted from the sources into a format that can be used by either Business Intelligence (BI) tools or migrate the data to a repository, or replicate data as a backup. In this phase, data is cleaned, mapped, and transformed—often to a specific schema—so that it satisfies operational requirements.
To start the transformation of the unstructured data, the data engineer needs to define the associations and correlations between the information they’ve extracted. For example, to analyze multiple rows and columns of data, you will need to begin by matching the current table rows and columns with the rows and columns of the other table data it needs to be associated with.
In order for data sets to be what is called “transcodeable”, it needs to align enough so that it can be sensibly and clearly compared and contrasted. It doesn’t have to include the exact same number of rows and columns, but it needs to at least share a basic common structure.
The fact that the data sets must be correct and full is another challenge.For example, in a healthcare use case, a precise dataset is necessary to ascertain how many staff members are available throughout the course of a given month to provide patient care. When the forecasting system tries to read a field that is blank or has falsified data, errors will be generated. The healthcare data repositories may rapidly get enmeshed in a “data swamp” if the data sets are not proper.
Moreover, the transformation process entails several types of changes that ensure the quality and integrity of data. Data is not usually loaded directly into the target data source, but instead it is common to have it uploaded initially into a staging database.
This step ensures a quick roll back in case something does not go as planned. During this stage, you have the possibility to generate audit reports for regulatory compliance or diagnose and repair any data issues.
Load
The process of writing converted data from a staging area to a target database—which may or may not have existed before—is known as the load.This procedure could be relatively straightforward or extremely complicated, depending on the requirements of the application. These processes can all be completed using ETL tools or by using custom code.
The loading procedure corresponds to importing your converted data into your data warehouse or another convenient location for your company.
You can load it all at once, which is known as full loading, or you can load data incrementally or in real-time.
Batch loading is often preferred, as it’s easier to manage and doesn’t put too much strain on your data warehouse or the data lake. Additionally, it also avoids data duplication by verifying the database before creating new records for any incoming data.
Challenges of ETL Pipeline
Fundamentally, data engineers created ETL tools for people who can understand and operate data tools. As a result, the methods for data transformation are often only available to IT staff and not to data consumers because they need extensive skills to install, implement, and manage.
ETL tools are doing the “power lifting” to get data into a standardized warehouse and the data consumers have access to the finished product in the Data Warehouse.
Although ETL tools function reasonably well in business specific data warehouse setups, it creates a bottleneck in processing requests from users outside the enterprise and in adding external data sources. As we’ll see below, there are more challenges which ETL technique particularly struggles with.
Big Data Processing led to ETL burnout
It is estimated that around 80% of the data collected by organizations are in unstructured format and is growing every year. While the data collection increases, only around 27% of the data is actually used for any analytics or decision-making projects.
The capacity, resources, cost, and timeliness of the conventional ETL were severely tested to the breaking point by the three V’s of big data (velocity, volume, and variety). In essence, ETL simply couldn’t keep up.
Limited Memory for Storage
ETL tools have limited CPU or memory. Hence it creates obstruction in data processing.
Struggle with Governing Data
ETL significantly contributes to the accessibility of enterprise data sources. But unlike the conventional, business specific data warehouse controlled by data engineers, achieving adequate data governance is a significant difficulty when working with a diversity of external data sources.
ETL lacks Normalization
ETL tools have trouble normalizing data in your data warehouse or data lake. Data consumers seek information that can be used immediately.
Normalization is the process of organizing data in a database. This includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating redundancy and inconsistent dependency.” according to the definition.
This information needs to offer a “one version of the truth” that data consumers can rely on in order to be acceptable. Data normalization should be used in addition to ETL rather than as a stand-alone method to achieve this level of precision.
Getting the transition process just right is not always simple. Poorly programmed mappings will inevitably result in a number of problems, including missing values and useless data. Garbage in, garbage out is a term used in data engineering to basically state that if you have terrible data, you’ll receive bad insights.
In short, ETL is best suited for processing smaller enterprise-wide data sets that demand intricate transformations and have already been identified as pertinent to the analytical aims.
On the other hand, ELT is highly suited for processing both structured and unstructured big data since it can handle any size or type of data.
What is an ELT Pipeline?
Another method of integrating data is called ELT, or “Extract, Load, Transform,” and it functions similarly to ETL, or “Extract, Transform, Load.” This procedure transfers unprocessed data from a source system to a resource, like a data warehouse.
ELT is designed for big data and cloud repositories, with clear benefits in scalability, performance and cost, but with some risks in data governance. ELT tools, in contrast to ETL, are created with the data consumer in mind.
They are made to offer selected, simple-to-understand modifications that enable transparent, on-demand access to several data sources in any storage format. The idea behind ELT tools is that they are facilitators of data access.
Extract & Load
Unlike ETL, ELT allows for the extraction of unstructured data (along with structured and semi structured data) from a source system and load it onto a target system. There is no requirement for data staging because the extracted, unstructured data is made available to business intelligence systems.
Fundamental data transformations, such as data validation and duplicate data removal, are carried out by ELT employing data warehousing. These processes are real-time updated and used for massive amounts of unprocessed data.
A data warehouse is a central collection of data that can be examined to help decision-makers become more knowledgeable. In contrast to a traditional database’s simple transactional queries, a data warehouse is designed with complex analytics query optimization in mind.
When working with data scientists, another form of infrastructure is required: a data lake. Focus on the fact that a data warehouse only keeps structured data used to track specific KPIs.
A data lake, however, is the exact opposite. It’s a different kind of storage that maintains the data in its original state without preprocessing it or applying a predetermined template.
Transform
The extracted data is loaded into the target system or data repository, and transformations are applied in the data repository. The destination system could be a data warehouse or data lake. This stage can involve the following:
- Filtering, cleansing, de-duplicating, validating, and authenticating the data.
- Utilizing the raw data to do computations, translations, data analysis, or summaries. This could involve anything from consistent row and column header changes to currency or measurement unit conversions, text string altering, adding or averaging values, and anything else required to meet the organization’s unique BI or analytical needs.
- Deleting, encrypting, concealing, or otherwise safeguarding data that is subject to governmental or commercial laws.
- Transforming the data into tables or connected tables in accordance with the warehouse’s deployed schema.
ELT is a relatively new technology in data engineering powered by cloud technologies. It helps to process large sets of data. Moreover, ELT has an advantage over ETL since the raw data is delivered directly to the destination system rather than a staging environment. This shortens the cycle between extraction and delivery.
Conclusion
The role and scope of data engineering services has expanded with the complexity, volume, and the need for compliance with privacy regulations. Today, data governance and data science initiatives greatly influence the role and structure of data engineering projects.
The earlier methods of ETL, however, were unable to keep up with the needs for quick processing, as data volume has increased tremendously. ELT (is actually ELT-L) is now more preferred over ETL, to address the complexity of the big data landscape.
The future of intelligent data pipelines would aim to enhance its ability to get high-quality, trusted data to the right data consumer at the right time in order to facilitate more timely and accurate decisions.
Structured or unstructured data, Factspan cloud and data engineering services help enterprises to create a business-ready scalable and reliable data pipeline.
Want to talk to a data engineering expert? Contact us.

Fractional AI and the Future of Enterprise GenAI S...

Multi-Agent Healthcare Ecosystems for Smarter and ...

Enterprises are Turning to Compact Models in AI...


Smarter Healthcare Analytics with Snowflake and Ic...

Analytics Unplugged: Navigating The Tension Betwee...

Serverless Computing in Snowflake...

A Complete Guide on Security and Compliance in Sno...

Enhancing Data Processing with Aggregate Functions...
