
Why this blog?
Are you trying to learn to develop efficient and effective NLP adaptation? In a world where time and resources are precious, LoRa offers a streamlined approach to tackle computational costs, training times, and memory requirements. Discover how LoRa opens doors to rapid experimentation, deployment in resource-constrained environments, and optimization for memory-limited devices. This blog section serves as your guide to unlocking the full potential of NLP adaptation, empowering you to stay ahead in the curve in language processing.
LoRA Optimizes Language Model Adaptation With Precision
In natural language processing (NLP), the ability to fine-tune large language models (LLMs) for specific tasks is paramount. However, traditional fine-tuning methods often come with significant computational costs and memory requirements, making them less feasible in resource-constrained environments. LoRa (Low-Rank Adaptation) is a recent and promising technique that transforms the fine-tuning process by introducing efficiency without compromising performance.
Traditional Fine-Tuning vs. LoRA Fine-Tuning
Traditional fine-tuning involves modifying all parameters of a pre-trained LLM to adapt it to a specific task. This approach, while effective, can be computationally expensive and data- intensive. LoRa fine-tuning, on the other hand, takes a more streamlined approach. Instead of adjusting all parameters, LoRa introduces two smaller matrices, known as the “adapter,” which capture the essential task-specific adjustments. By focusing on these key changes, LoRa significantly reduces the computational burden associated with fine-tuning.
The LoRA Fine-Tuning Process
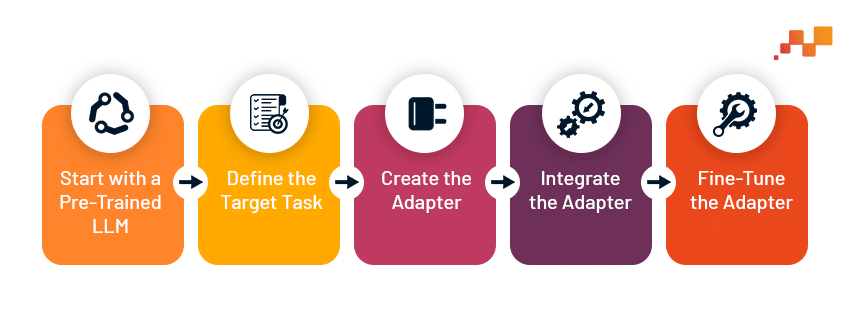
- Start with a Pre-Trained LLM: The process begins with a pre-trained LLM, such as GPT-3, which serves as the foundation for further adaptation.
- Define the Target Task: Identify the specific task for which the LLM needs to be fine- tuned, such as text summarization or sentiment analysis.
- Create the Adapter: Two smaller matrices, denoted as A and B, are crafted to capture the necessary adjustments for the target task.
- Integrate the Adapter: The adapter matrices are seamlessly incorporated into the architecture of the pre-trained LLM.
- Fine-Tune the Adapter: Only the parameters within the adapter matrices are trained using task-specific data, minimizing computational costs and training time.
AWS Data Engineering Essentials Guidebook

Benefits of LoRa Fine-Tuning
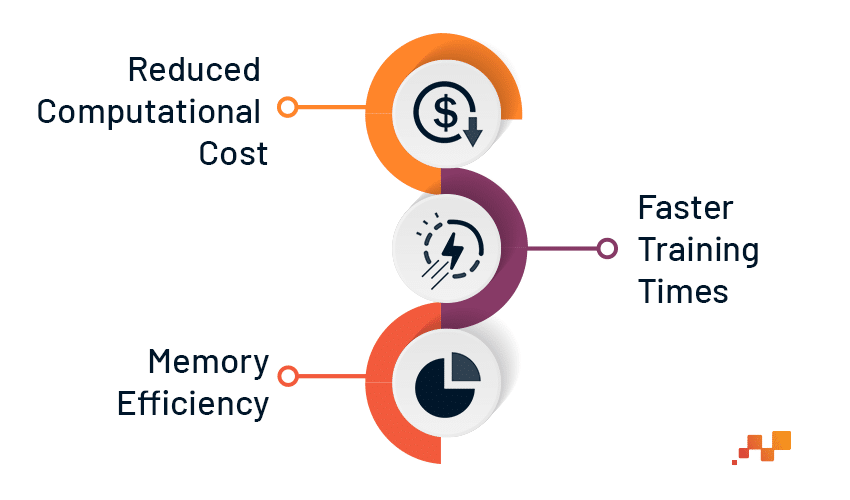
- Reduced Computational Cost: By focusing on a smaller subset of parameters, LoRa fine-tuning significantly reduces the computational resources required. This makes it particularly suitable for resource-constrained environments where traditional fine- tuning methods may be impractical.
- Faster Training Times: LoRa fine-tuning typically converges faster than traditional methods due to the smaller number of parameters being trained. This accelerated training process allows for rapid experimentation and iteration on different fine- tuning tasks.
- Memory Efficiency: The smaller size of the adapter matrices translates to lower memory requirements compared to modifying all parameters of the pre-trained model. As a result, fine-tuned models can be deployed on devices with limited memory, expanding their applicability across various platforms and devices.
- Reduced Catastrophic Forgetting: One of the key challenges in fine-tuning large language models is catastrophic forgetting, where the model loses its original knowledge during adaptation. LoRa helps mitigate this issue by preserving the core structure of the pre-trained model, thus minimizing the risk of forgetting important information.
Applications and Implications
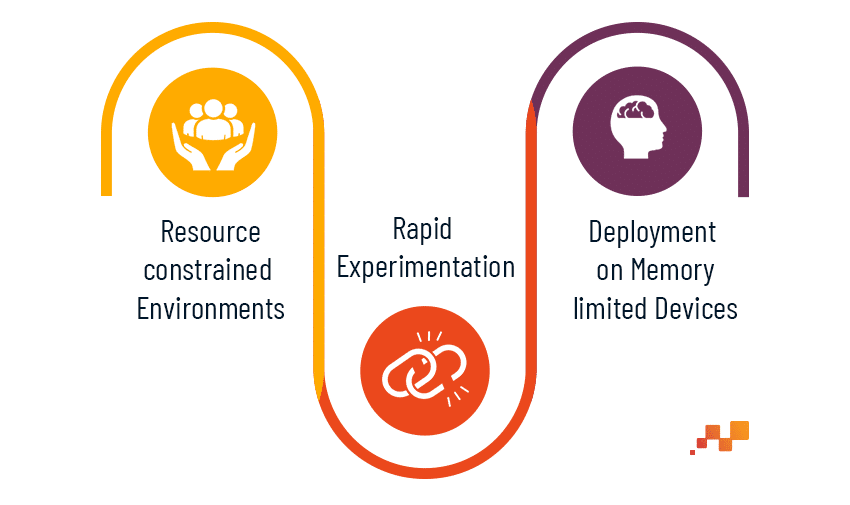
LoRA fine-tuning offers a compelling approach for a wide range of applications and
scenarios:
Advanced Prompt Engineering with ChatGPT Frameworks
- Resource-Constrained Environments: In settings where computational resources are limited, such as edge devices or low-power servers, LoRa fine-tuning enables efficient adaptation of LLMs without excessive overhead.
- Rapid Experimentation: Researchers and practitioners can leverage LoRa fine-tuning for swift experimentation with different fine-tuning tasks, accelerating the development and deployment of NLP solutions.
- Deployment on Memory-Limited Devices: With its reduced memory footprint, fine- tuned models using LoRa can be deployed on devices with constrained memory, including smartphones, IoT devices, and embedded systems.
The LoRa Advantage is a Faster, More Cost-Effective NLP Model Adaptation
LoRa fine-tuning is an innovative approach that offers a more streamlined and cost-effective way to adapt large language models to specific tasks. Unlike traditional methods that require extensive model re-training, LoRa focuses on targeted adjustments through smaller, highly optimized “adapter modules.” These modules essentially “learn” the nuances of the specific task, leading to significant improvements in efficiency. The benefits of LoRa are clear. Training times plummet, computational costs decrease, and memory usage becomes more manageable. As NLP continues its rapid development, LoRa stands out as a key technique for unlocking the full potential of large language models. By enabling faster and more targeted adaptation, LoRa paves the way for a wider range of real- world applications, pushing the boundaries of what’s possible in the field.
