
By the end of 2020, 70% of the industries going to rely on a Hadoop cluster for running more than 1000 nodes. All are running around 80% of unstructured data on 20% of structured data. If we take social media as an example, Twitter produces around 7TB data per day, where Facebook produces around 500TB data per day. So, is it easy to make statistical analysis easy than it appears? We already read about Future of Big Data in big data series part 1, let’s explore Hadoop and Hadoop Architecture.
Hadoop
Hadoop is an open-source project/utility used for solving the massive amount of data and computation. It was written in Java. Apache Software Foundation developed Hadoop on April 1’2006. It runs on a cross-platform operating system. Storage Part (HDFS) and MapReduce are the part of Hadoop Core which when divided into large blocks. These blocks distributed across nodes in a cluster. Then, to process data in parallel, it transfers Packaged Codes into Nodes which takes advantage of data locality. Here, Nodes manipulate the data they have access to. This permit data sets to process efficiently and faster.
HADOOP’S NAME AND LOGO IN LIGHT
Hadoop was named after a yellow Hadoop. It was an extinct species of Mammoth. Doug Cutting once said, “Hadoop was named a yellow elephant my kid was playing with. It was relatively easy to spell and pronounce, meaningless and not used elsewhere- all were my criteria for naming it. Kids are good at naming such and even Google is a kid’s term.”.

Hadoop Ecosystem
Hadoop Ecosystem is large coordination of Hadoop tools, projects and architecture involve components- Distributed Storage- HDFS, GPFS- FPO and Distributed Computation- MapReduce, Yet Another Resource Negotiator.
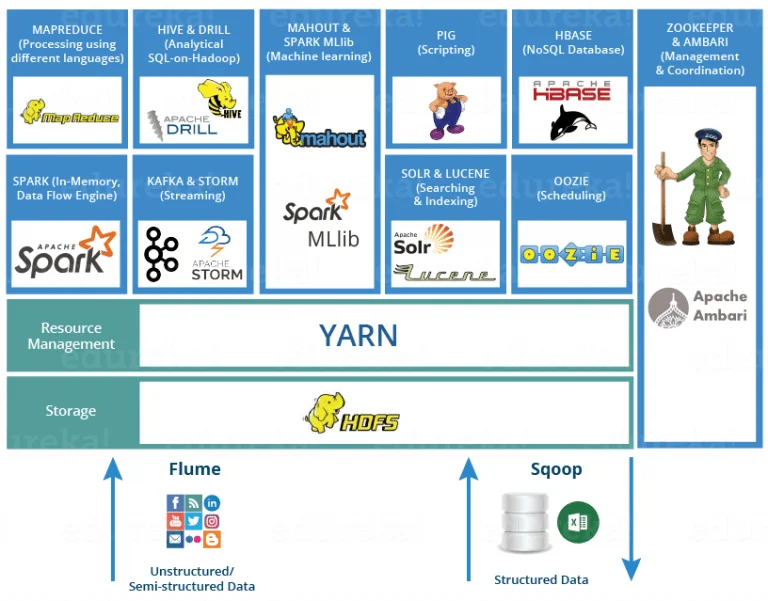
Recapitulation to Hadoop Architecture
Hadoop Architecture is a popular key for today’s data solution with various sharp goals. It runs on different components- Distributed Storage- HDFS, GPFS- FPO and Distributed Computation- MapReduce, YARN. It is a Master-Slave topology. One Master Node which assigns a task to various Slave Nodes which do actual configuration and manage resources. Master Nodes have metadata and slave nodes keep real data.

PROPERTIES
Hadoop project comes with amazing and very flexible properties to talk about. Here are some of these features:
Open-source utility- Codes modification can be done according to any business requirement. Being an Open source is a very efficient feature of Hadoop.
Distributed Processing- Storage and distribution are parallel across the cluster which make data identity finer.
Infallible- Cluster machine stores the data infallibly. This is all due to the replication of data in the cluster. It is beneficial in the case of machine failure or machine gets down
Fault-Tolerance- It manages to change according to the changes where default 2 replicas of each block are stored across the cluster.
Ascendable- Hadoop is horizontally scalable. New nodes easily added to the fly easily without getting down.
High Availability- Machine failure does not affect data availability. This is due to storing multiple copies of data.
Easy Access- It is easy to modify (coding) according to a business requirement which makes it more flexible. The framework takes care of all the things so there is no need for a client for distributed computing.
Data Locality- Hadoop works on data locality principle. It moves computation to data instead of data to the computation which made it easy to handle big data.
Economic- It does not need any specialized machine. It runs on commodity hardware which makes it very cost-friendly. Adding Nodes on the fly is also not so expensive.
Components of Hadoop Architecture
With developing series of Hadoop, its components also catching up the pace for more accuracy. Hadoop runs on the core components based on,
Distributed Storage– Hadoop Distributed File System (HDFS)
Distributed Computation– MapReduce, Yet Another Resource Negotiator (YARN).
Let’s discuss more of Hadoop’s components.
Distributed Storage
Distributed storage is the storage vessel of the Hadoop in a distributed fashion. It consists of Hadoop Distributor File System (HDFS) and GPFS- FPO. These divided into many blocks across the cluster. Then, it further runs throughout the Nodes.
HADOOP DISTRIBUTED FILE SYSTEM- HDFS
Hadoop Distributed File System (HDFS) is the data storage for Hadoop. It converts data into smaller units called blocks. It stores data in a distributed manner. Hadoop Distributed File System (HDFS) has a Master-Slave architecture so it runs on two daemons, Master nodes- Name Nodes and Slave Nodes- Data Nodes.
Nodes- Nodes in Hadoop architecture are generally used for processing and storing. Hadoop Distributed File System (HDFS) has two types of daemons, Master nodes- Name Nodes and Slave Nodes- Data Nodes. The stored files distributed in the nodes across the cluster.
NameNodes: Name Nodes run on the Master server. It oversees Namespace management and synchronizes file access by the client. It heads modification to file system namespace. Name nodes also keep track of the mapping of blocks to Data Nodes.
DataNodes: It runs on Slave nodes. Data Nodes main business is to store the main data. It first splits input data into a number of data blocks and stores on a group of slave machine. It also reads/writes request from the file system’s client. When any demand from Name nodes generate, it creates, deletes and replicates blocks.
Blocks- Blocks are the smallest unit of storage. these are the contiguous storage assign to a file in a computer system. Hadoop has already a default block size of 128MB and 256MB. One should be careful while choosing block size. As it converts data into metadata, so it can generate a problem when it comes to small data.
Replication Management- It is a fault tolerance technique of HDFS. It creates copies of the blocks and then stores in different data nodes. Replication Management makes decisions of storing amounts of copies of the blocks. By default number of storage is 3 but one can configure it accordingly.
Rack Awareness Algorithm- A rack is consists of many Data nodes machine. There are several such racks are in production. HDFS ensue Rack Awareness Algorithm. It places replicas of the blocks in a distributed manner. Rack doesn’t allow the storage of more than 3 blocks.
Distributed Computation
Distributed computation is the estimation and evaluation vessel of the Hadoop architecture in a very distributed manner. It consists of MapReduce and Yet Another Resource Negotiator (YARN). It runs throughout the Nodes.
MAPREDUCE
MapReduce is also the main component of Hadoop architecture as HDFS. Google avail MapReduce in instance actions. It analyses the stored HTML content of websites by counting all the HTML tags and words along with combinations. Java made the implementation really easy and flexible.
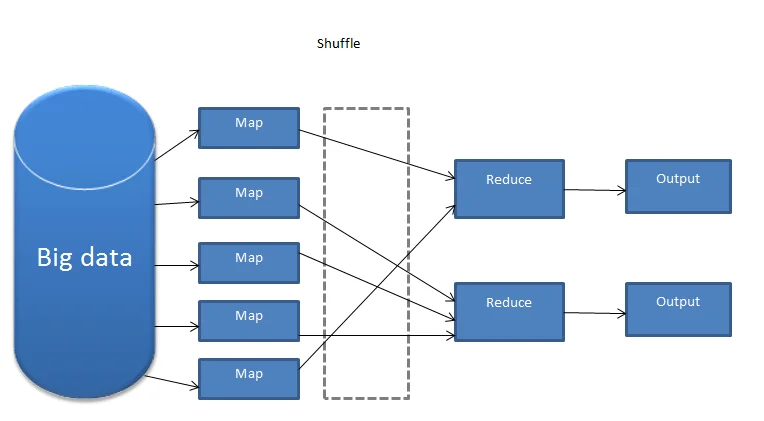
How does MapReduce work?
MapReduce works in a parallel way. Data is processed in two phases in MapReduce, Map Phase and Reduce Phase. Map Phase loads and transforms input data into key/value pairs. It reads all the data from HDFS. Then, it sends key/value pairs to the reducer. Each dataset is known as an input record. Reduce Phase compute the data and stores the results. Storage can either be back HDFS, database or any other database form. Both of these phase run parallelly across the cluster.
MapReduce Functionality
JobTracker: It creates and runs the job on the Namenodes allocates the job to task tracker. Job Tracker is a master oversees the jobs done. It is responsible for taking client requests.
TaskTracker: TaskTracker tracks resources availability and life cycle management. It also keeps track of progress and fault tolerance. It has to report the status of all tasks to Job Tracker.
YARN
Yet Another Resource Negotiator is the management layer of the Hadoop cluster. YARN is based on the principle of separation of resources management and job scheduling/monitoring functions into various daemons. It has at least one Global Resource Manager and per Application, whether it can be a single job or DAG jobs.
It works on the Resource Manager and Node Manager. Node manager manages the resource usages by the input vessel and the report the same to Resource Manager. Resources can be discs, networks, CPU and many more.
Node Manager- It keeps track of the various nodes running across the cluster. Node manager manages the resource usages by the input vessel and the report the same to Resource Manager. Resources can be discs, networks, CPU and many more.
Resource Manager- It is further divided into Scheduler and Application manager/Master.
Scheduler- It administers resources to several applications on the basis of its requirement. Scheduler does not track the status of the application.
Application manager/Master- Application manager accepts job submission. It negotiates the very first container for executing Application Master. If fails, it restarts the Application Master container. Application master tracks the status of the resource container.
Open-source projects in the Hadoop Ecosystem
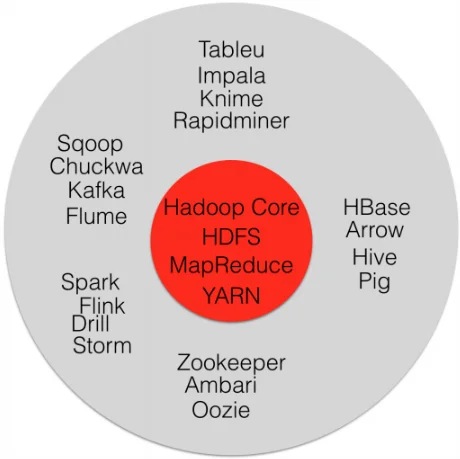
HBase- H.Base is a Hadoop non-relational distributed database. It uses a distributed file system for storing big data and MapReduce codings for computing fractionally.
Hive- Hive is a data warehouse software provides tools to extract, transfer and load the data. Then, querying this data stored in Hadoop files.
PIG- PIG is a high-level language which generates MapReduce codes to analyse large datasets.
Zookeeper- Zookeeper is another Incubator project of Apache Hadoop which provides distributed search functionality and for processing the data.
Eclipse- It is a text search library. Eclipse is an IDE mainly used for JAVA programming. It is installed and configures for the MapReduce functionality.
Lucene- Lucene is the Incubator project of Apache Hadoop which provides distributed search functionality. It is also a text search library.
Ambari- Ambari is the project of Apache Hadoop which manages/monitors/visualizes the status and progress of every application running over the cluster. It is very flexible and scalable.
There are many other projects in the Hadoop ecosystem like Oozie, Storm and so on.
Conclusion
Discussing Hadoop and Hadoop architecture is never-ending talk. Hadoop answeres many big data queries. Why evaluating big data and how? It is not the complication anymore with Hadoop. With the upcoming versions, it is growing more with its functionality and versatility. Now, Hadoop architecture is making more possibility of solving massive data.
About The Author
Chaitanya Murali is a Senior Business Analyst at Factspan who has a broad spectrum of the domain and technical knowledge. He has proven success in bringing added value to companies through analytics and data science across multiple industries & domains. Apart from travel mania and adventures, Chaitanya is very curious about new learnings and loves to read fictional books.

AI Co-Engineer for the Data Engineering Lifecycle...

Operational Data Platform Implementation for a Glo...

Building Scalable Data Pipelines with Alteryx and ...

Scaling Licensing Revenue Operations for a Global ...

Agentic Test Automation for QA Acceleration Using ...

An Enterprise Framework for ROI-Driven Agentic AI...

Fast‑Tracking Cloud Migration of Legacy Assets w...

Fractional AI and the Future of Enterprise GenAI S...

Multi-Agent Healthcare Ecosystems for Smarter and ...
