
Can you imagine a place where nothing is organised or stored in a distributive way? Ever wondered that what if every stuff from the kitchen, bathroom, bedroom, dining room and drawing room stored in a place haphazardly. Isn’t it making things more complicated and uneasy? Same theory goes with big data application, Hadoop. Hadoop also needs a distributed storage system, Hadoop Distribution File System (HDFS), making the whole process easy.
Introduction to Hadoop Distribution File System- HDFS
Hadoop cluster has a primary distributed data storage system. Hadoop distributed File System (HDFS) which is based under Distributed Storage. HDFS is designed to run commodity hardware patterned after the UNIX file system. It doesn’t end here. It is eminently fault-tolerant. HDFS is designed to be employed on inexpensive hardware.
It is suitable for large dataset over the small dataset. HDFS profers high outturn access to the application data. It relieves a few POSIX requirements to enable transmitting access to data of the file system. HDFS is structured for Nutch Web Search Engine Projects. It is now Apache’s Hadoop subproject.
Hdfs and Hadoop
Hadoop Distributed File System (HDFS) is a convenient data storage system for Hadoop. It converts data into smaller units called blocks. It stores data in a distributed manner across the cluster. Hadoop Distributed File System (HDFS) has a Master-Slave architecture as we read before in Big Data Series Part 2. So it runs on two daemons, Master nodes- Name Nodes and Slave Nodes- Data Nodes.

Why Hdfs?
Hadoop Distribution File System (HDFS) is the part of Hadoop Core which when divided into large blocks. It is the part of a Distributed Storage System. These blocks distributed across nodes in a cluster. Then, to process data in parallel, it transfers Packaged Codes into Nodes which takes advantage of data locality. Replication of data in the cluster is beneficial in the case of machine failure or machine gets down. It stores multiple data copies. Here, Nodes manipulate the data they have access to. This permit data sets to process efficiently and faster.
Key Features
Hadoop Distribution File System has very prominent key features which enhance Hadoop’s functions. Here are the six diversely amazing features of Hadoop Distribution File System (HDFS) given below.
Distributed Processing- Storage and distribution are parallel across the cluster which make data identity finer.
Infallible- Hadoop Distribution File System stores the data infallibly in the cluster. This is all due to the replication of data in the cluster. It is beneficial in the case of machine failure or machine gets down.
Fault-Tolerance- Hadoop Distribution File System manages to change according to the changes where default 2 replicas of each block are stored across the cluster.
Replication- Replication is the HDFS’s important feature as it protects from the loss of data during unfavorable condition like a failure of hardware.
Ascendable- Hadoop Distribution File System in Hadoop is horizontally scalable. New nodes easily added to the fly easily without getting down.
High Availability- Machine failure does not affect data availability. This is due to storing multiple copies of data in Hadoop Distribution File System.
Hdfs Working
Hadoop Distribution File System (HDFS) is the part of Hadoop Core which when divided into large blocks. It is the part of a Distributed Storage System. These blocks distributed across nodes in a cluster. Then, to process data in parallel, it transfers Packaged Codes into various Name Nodes which takes advantage of data locality. Name node further splits into Data nodes directories.
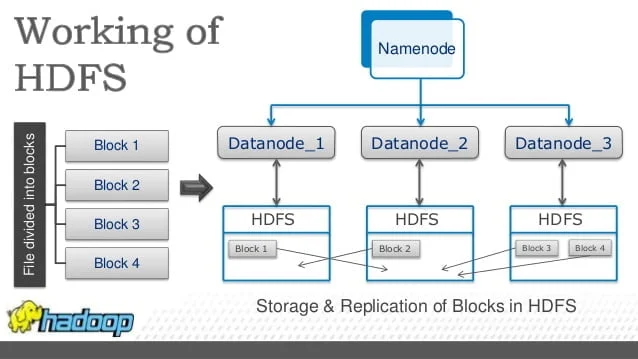
Replication of data in the cluster is beneficial in the case of machine failure or machine gets down. It stores multiple data copies. Here, Nodes manipulate the data they have access to. This permit data sets to process efficiently and faster.
Hadoop Distribution File System- HDFS Architecture
Hadoop Distribution File System (HDFS) has a very descriptive architecture which includes Name Nodes & Data Nodes, Image & Journals, HDFS Client, Backup Node, Checkpoint Node, Upgrades & File System Snapshots.
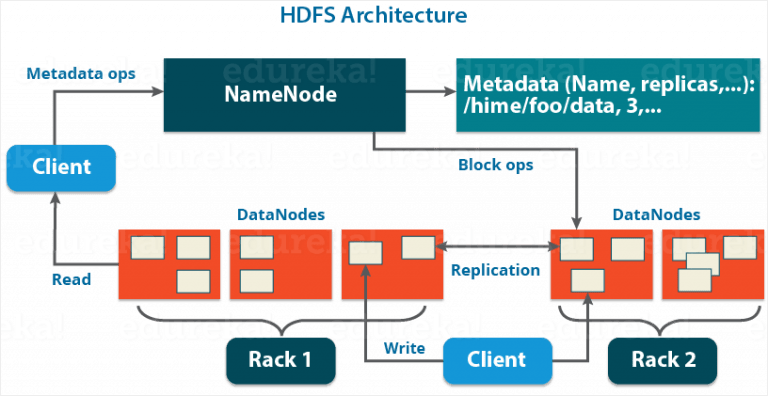
Name Nodes & Data Nodes
If reading about HDFS, one should be clear about Name Nodes i.e. it runs on the Master server. It oversees Namespace management and synchronizes file access by the client. Nodes in Hadoop architecture are generally used for processing and storing. Hadoop Distributed File System (HDFS) has two types of daemons, Master nodes- Name Nodes and Slave Nodes- Data Nodes. The stored files distributed in the nodes across the cluster. Name Node heads modification to file system namespace. Name nodes also keep track of the mapping of blocks to Data Nodes. Technically, Data Nodes run on Slave nodes. Data Nodes concerned to store the main data. It first splits input data into several data blocks and stores on a group of slave machine. It also reads/writes request from the file system’s client. When any demand from Name nodes generate, it creates, deletes and replicates blocks.
Image and Journals
Images are the Inodes and list of Blocks which define the metadata of the name system. Name node keeps all the Namespaces in RAM. Track of the image is recorded in Checkpoint. The tenacity of the checkpoint doesn’t include the location of block replicas. Journal tracks the client-initiated transaction. It is flushed and synced before sending a grant to the client. Redundant copies of the journals are stored for increasing durability.
Hdfs Client
Hadoop Distributed File System (HDFS) Client is the library which helps user application to access the file system. It exports the HDFS file system interface. Conventionally, HDFS supports operations to read, write, rewrite, delete files, create and also for deleting directories. It stores blocks in such a manner to which it eases HDFS to expose the location with the help of API.
Backup Node
Backup node is like the checkpoint node. It has the capability of creating periodic checkpoints. Backup Node also maintains the in-memory images of the file system namespace. It always syncs with the state of name nodes.
Checkpoint Node
Checkpoint node is the local native file system that records the track of the images. Its host is very different from the name nodes. The tenacity of the checkpoint doesn’t include the location of block replicas as its main purpose is to serve the client requests.
Upgrades and File System Snapshots
When upgrades the file system, the probability of corrupting file system increases. It can happen due to any software bug or human mistakes. The snapshot mechanism saves the present state of the file system.
Some Hadoop Ecosystem Components
Hive
Hive is a data warehouse software provides tools to extract, transfer and load the data. Purpose of building Hive is for data queries and analysis. Then, querying this data stored in Hadoop files. It gives SQL like interface.
Nosql
NoSQL stands for Not Only SQL database which is an alternative to traditional relational data. It can aid a huge range of data models. NoSQL includes key values, graph formats, columnar and documents along with these models. Before building a database, data is placed and data schema is designed carefully.
Closure
In February 2019, Apache released the latest Alpha version of Hadoop 3.x series. This version has enhanced HDFS in various ways. It came along with more than two name nodes. Also, it improved data nodes as Intra balancer. It profers the easiest way to configure data. Moreover, data nodes in a cluster are advanced to manage the storage. With growing time, its scalability is getting sharper.

AI Co-Engineer for the Data Engineering Lifecycle...

Operational Data Platform Implementation for a Glo...

Building Scalable Data Pipelines with Alteryx and ...

Scaling Licensing Revenue Operations for a Global ...

Agentic Test Automation for QA Acceleration Using ...

An Enterprise Framework for ROI-Driven Agentic AI...

Fast‑Tracking Cloud Migration of Legacy Assets w...

Fractional AI and the Future of Enterprise GenAI S...

Multi-Agent Healthcare Ecosystems for Smarter and ...
